A prototype is fun. Production is serious. Running large language models in real products means building for safety, cost control, and reliability. Treat the model like any other critical system.
Start with a narrow, valuable scope
Pick one job where an LLM is the best tool.
- Clear user problem and success metric
- Bounded inputs and outputs
- Known failure modes and safe fallbacks
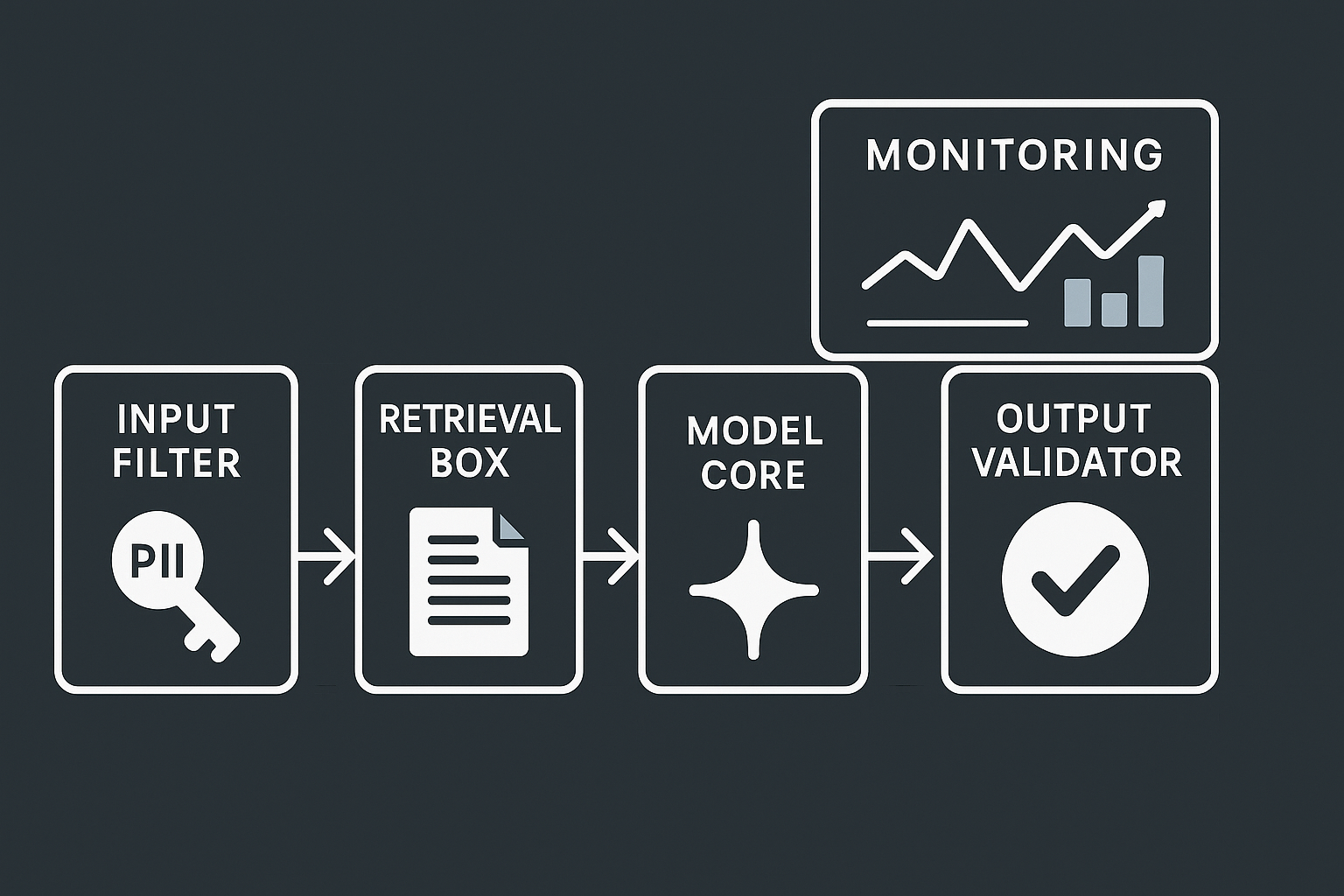
Control inputs before they hit the model
Garbage in creates chaos out.
- Sanitize and normalize user text
- Strip secrets and redact PII
- Add guard checks for prompt injection patterns
- Enforce size limits with truncation rules
Constrain outputs to fit the product
Make results predictable and safe.
- Use structured prompts and schemas
- Validate JSON before use
- Apply output filters for safety and policy
- Provide human review for high impact actions
Layer retrieval only when it pays off
RAG should solve a real gap.
- Start with a small, curated knowledge set
- Add chunking and embeddings with clear versioning
- Log sources and surface citations to users when helpful
- Monitor retrieval accuracy, not just model quality
Build an evaluation harness early
You cannot manage what you do not measure.
- Golden tests for correctness and safety
- Scenario sets for tricky edge cases
- Automatic scoring and pass gates in CI
- Track regressions across model or prompt changes
Design for cost from day one
Costs scale fast with traffic.
- Cache deterministic responses by prompt key
- Choose context sizes based on real value
- Route by request type to cheaper models when possible
- Batch low urgency work to reduce overhead
Roll out with feature flags
Reduce risk while you learn.
- Internal only, then small cohorts
- Canary by route, customer tier, or geography
- Shadow mode to compare against existing behavior
- Instant kill switch if metrics slip
Observe everything in one place
Debugging blind is expensive.
- Log prompts, tools called, and outputs with hashes
- Track latency, error rate, token use, and safety events
- Set alerts on cost spikes and accuracy drops
- Add tracing so a bad output can be reproduced
Keep humans in the loop where it counts
Humans handle nuance and edge cases.
- Queue sensitive outputs for approval
- Give reviewers context, deltas, and one click actions
- Capture feedback to improve prompts and rules
Plan for incidents and recovery
Bad outputs will happen. Respond fast.
- Clear playbooks and on call rotation
- Rollback prompts, model versions, or flags
- Communicate quickly and transparently with customers
- Post mortems that update tests and policies
LLMs in production succeed when scope is focused, inputs and outputs are constrained, quality is measured, and rollouts are controlled. Observe everything and keep a safe escape hatch. If you want a production plan that balances value, safety, and cost, ping us at Code Scientists.