Your architecture shapes delivery speed, reliability, and cost. Request-driven designs are simple and predictable, while event-driven designs are flexible and scalable. The right choice depends on your product, team, and risk profile.
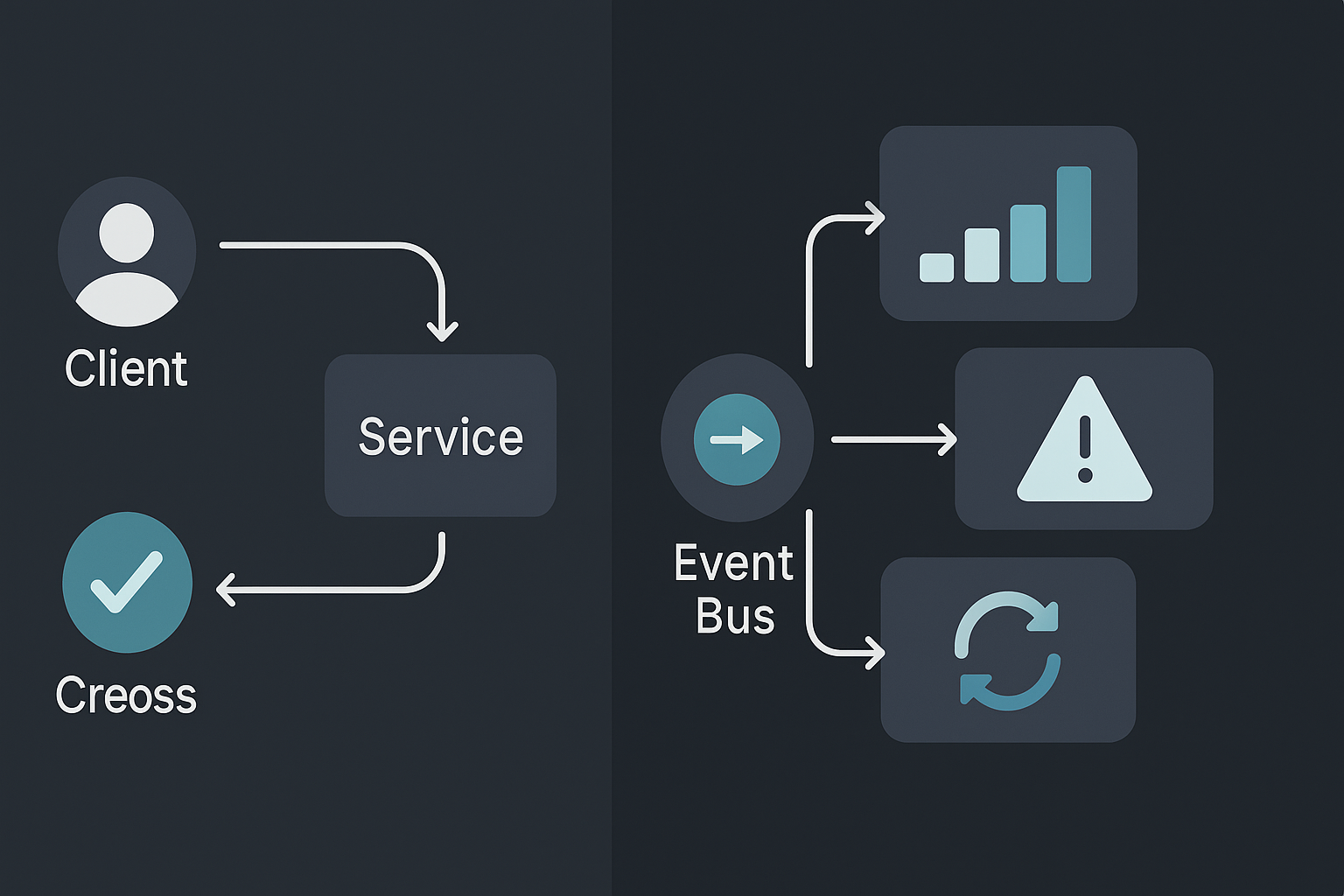
What request-driven does well
A client calls a service and waits for a response. This is simple, synchronous, and easy to reason about.
- Great for APIs, dashboards, and user actions that need instant answers
- Easy debugging and tracing with a single call path
- Straightforward timeouts, retries, and error handling
Where request-driven strains
- Long-running tasks tie up resources or hit timeouts
- Cross-service chains become fragile and slow
- Spikes cause contention that hurts tail latency
What event-driven does well
A producer publishes an event, and consumers react asynchronously. Loose coupling and natural scaling.
- Ideal for workflows like order processing, billing, notifications, analytics
- Each consumer scales independently and fails without taking others down
- Natural audit trail via immutable event logs
Where event-driven strains
- Harder to debug without good observability
- Event schemas and versioning require discipline
- Eventual consistency demands careful UX and idempotency
- More moving parts to secure and operate
A simple chooser
- Pick request driven when the user waits, and correctness is immediate. Examples: authentication, search results, pricing checks.
- Pick event-driven when work can run in the background. Examples: sending emails, generating reports, settlements, and data ingestion.
Hybrid patterns you can ship now
- Synchronous front, async back: return fast, enqueue work, update status later
- Outbox pattern: write data and event together to avoid lost messages
- Saga pattern: orchestrate multi-step workflows with compensating actions
- CQRS light: keep a read model updated by events for fast queries
Data and consistency guidelines
- Design events as facts, not commands
- Version event schemas and keep them stable
- Use idempotent consumers with deduplication keys
- Make user facing status clear if the work is still processing
Observability and reliability
- Correlate request IDs with event IDs
- Emit structured logs and metrics for publish, consume, fail, and retry
- Set sane DLQ rules and alert on age and size, not just count
- Run game days that simulate consumer failure and backlog recovery
Security and cost
- Protect brokers like any critical datastore
- Scope credentials by topic or stream
- Track per-event cost and backlog storage to avoid surprises
- Right size partitions and retention based on throughput and recovery needs
Migration tips without the rewrite
- Start by eventing audit friendly domains like analytics and notifications
- Introduce an outbox table to publish changes safely
- Move one long-running job out of the sync path first
- Add a lightweight status endpoint so clients do not poll your core API
You do not need to pick a single style forever. Use request-driven paths for fast answers and event-driven flows for background work and scale. If you want an architecture plan that matches your roadmap without overcomplicating delivery, ping us at Code Scientists.